Airflow는 Executor의 구성에 따라 Airflow 컴포넌트나 Task 실행 방식이 달라지는데,
이 글에서는 KubernetesExecutor를 중점으로 정리를 해보려고 한다.
그러기 위해 우선 널리 사용되는 CeleryExecutor를 간단히 살펴보자. 아래는 CeleryExecutor의 전체적인 아키텍처이다.
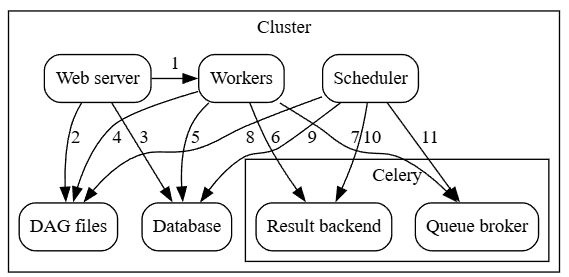
CeleryExecutor 방식에서는 Result Backend와 Queue Broker라는 컴포넌트가 보이는데, 이들은 각각 아래와 같은 역할을 수행한다.
- Queue Broker - task를 저장하는 역할
- Result backend - task의 상태를 저장하는 역할
아래 시퀀스 다이어그램을 보면, 각각이 어떤 일을 하는 건지 좀 더 이해가 쉽다.
queue broker는 task들의 대기열이며, result backend는 task들의 상태를 저장하기 위해 사용한다.

그렇다면 kubernetes 환경에서도 이러한 방식을 쓰면 안되는 걸까? 왜 굳이 kuberneteExecutor라는 방식이 따로 생긴 걸까?
결론부터 말하자면, kubernetes 환경에서도 CeleryExecutor 방식으로 구성은 가능하다.
다만 CeleryExecutor 구성으로는 kubernetes의 장점을 제대로 활용하지 못하기 때문에, kubernetes native한 구성이 필요했던 것이다.
KuberentesExecutor
KubernetesExecutor 동작
KuberentesExecutor의 기본적인 아키텍처는 아래와 같다.

CeleryExecutor 구성과는 달리 queue broker, result backend, worker 같은 구성요소가 빠져 있다는 것을 알 수 있다.
KuberenteExecutor에서는 각 task가 pod로 실행되기 때문에, 큐나 worker 같은 요소가 항상 상주하여 실행될 필요가 없는 것이다.

Airflow 스케줄러는 Kubernets API 서버를 watch(kubernetes watch API)하면서 task Pod 상태(시작, 실행, 종료, 실패 이벤트 등)를 알 수 있다.
그래서 만약 task가 메타 DB에 상태를 업데이트 하기 전 실패한다면, 아래와 같이 Kubernets watch API를 통해 알아차리고 DB에 업데이트 할 수 있다.

장점
KubernetsExecutor 방식은 (Kubernetes 장점이기도 한) 관리가 편리하다는 장점이 있다.
ReplicatSet등의 설정으로 일정한 pod수를 보장하며, pod가 올라가 있던 노드가 다운되면 알아서 다른 노드로 이동해 실행 시키는 것과 같이, Kuberentes가 어느 정도는 알아서 pod 관리를 해준다. 때문에 운영자의 시간이나 부담을 줄일 수 있다.
또한 지속적인 리소스의 점유가 줄어든다는 이점도 있다.
Worker가 실제로 사용되지 않는 때에도 task가 들어올 것을 대비해 항상 실행 되어야 할 필요 없이,
task가 생기면 pod가 실행되고, task 종료 시 알아서 자원이 회수된다.
특히 각 task는 pod라는 독립적인 환경에서 실행되므로 dependency 충돌 등의 문제도 해결될 수 있다.
단점
task가 생기면 pod가 생성되기 때문에, pod가 생성되어 실제 작업을 시작하기 전까지의 지연 시간이 생길 수 있다.
그래서 작업이 빠르게 처리되어야 하는 경우에는 항상 worker가 task를 대기하고 있는 CeleryExecutor 방식이 적합할 수 있다.
EOF.
'데이터 엔지니어링' 카테고리의 다른 글
| [Spark] Apache Spark 구조 및 Job 실행 과정 (0) | 2025.04.21 |
|---|---|
| [DB] SQL Processing (0) | 2019.11.21 |